Teoria do valor extremo (EVT da sigla em inglês) é um ramo da estatística que lida diretamente com eventos raros, extremos. Seu objetivo é modelar eventos que se distanciam muito da mediana de uma distribuição. Justamente por esta característica, a EVT está sendo utilizada para modelar riscos que possuem distribuição com caudas longas, um dos fatos estilizados que apresentamos sobre retornos de ativos financeiros.
No primeiro artigo desta sequência foi apresentada uma vasta revisão de literatura sobre a EVT e suas aplicações em finanças, com enfoque especial ao gerenciamento de risco. Neste artigo formalizaremos a teoria e serão apresentadas as equações para o cálculo tanto do VaR quanto do ES para um ativo financeiro. Também será abordada a diferença entre medidas incondicionais e condicionais de risco.
Ao utilizarmos a EVT, e mais especificamente o método conhecido como peaks over treshold – POT, estamos interessados em modelar apenas a parte da cauda da distribuição das perdas de um ativo financeiro maiores que um determinado valor de limiar u. É da modelagem desta cauda, portanto, que faremos as estimativas de risco VaR e ES.
Distribuição de valores extremos generalizada
Consideremos uma amostra de uma variável aleatória cujas observações sejam independentes e igualmente distribuídas (va iid) \(L_i,i\in \mathbb{N}\) que represente as perdas financeiras de um determinado ativo.
A EVT está interessada em investigar o comportamento da distribuição dos máximos desta va iid dados por \(M_n = \max (L_1, \ldots , L_n)\) para vários valores de \(n\) e a medida que \(n\rightarrow \infty\). A sequência \(M_n\) é chamada de máximos em bloco e é possível demonstrar que a única distribuição para a qual \(M_n\) converge com \(n\rightarrow \infty\) é a distribuição de valores extremos generalizada (GEV, da sigla em inglês).
Para tanto, é necessário normalizarmos esta sequência de máximos de forma que sua distribuição seja convergente para uma distribuição \(H(x)\) não-degenerada. Seja \(F(x)\) a distribuição original de uma variável aleatória iid, é possível normalizar seus máximos em bloco através da relação \(M_n^*=(M_n-d_n)/c_n\) de forma que:
\[\begin{equation}
\lim_{n \rightarrow \infty} P\left(\frac{M_n-d_n}{c_n} \leq x \right)
= \lim_{n \rightarrow \infty} F^n(c_nx + d_n)
= H(x)
\tag{1}
\end{equation}\]
Em outras palavras, para determinadas sequências \(c_n\) e \(d_n\) a serem escolhidas, existe uma distribuição de \(H(x)\) não-degenerada a qual representa a distribuição dos máximos em bloco de \(F(x)\).
A potenciação de \(F\) em \(n\) deriva diretamente da suposição que a variável aleatória é iid, enquanto que a transformação de \(x \rightarrow c_n x+d_n\) é a normalização dos máximos em bloco.
Definição 1 (Domínio de atração de máximos) Se a equação
(1) é válida para uma
\(H\) não-degenerada, então se diz que
\(F \in MDA(H)\),
\(F\) pertence ao domínio de atração de máximos de
\(H\).
Teorema 1 (Fisher-Tippett) Se \(F \in MDA(H)\) para alguma \(H\) não-degenerada, então \(H\) deve ser uma distribuição do tipo de valores extremos generalizada – GEV.
O teorema 1 foi estabelecido através de três artigos, Fisher and Tippett (1928), Gnedenko (1941) e Gnedenko (1943).
Definição 2 (Distribuição de valores extremos generalizada) É definida por sua p.d.f (função densidade de probabilidades) a qual é dada por:
\[\begin{equation}
H_\xi(x) =
\begin{cases}
exp(-(1+\xi x)^{-\frac{1}{\xi}}), & \xi \neq 0,\\
exp(-e^{-x}), & \xi = 0,\\
\end{cases}
\tag{2}
\end{equation}\]
O parâmetro \(\xi\) (leia-se qsi) é conhecido como o parâmetro de forma da distribuição e dependendo deste valor teremos diferentes tipos de distribuição (casos particulares da GEV). Quando \(\xi=0\) a distribuição resultante é uma Gumbel, quando \(\xi>0\) uma Fréchet surge, e por fim quando \(\xi<0\) temos uma Weibull.
Tomemos como exemplo a distribuição exponencial e calcularemos seu MDA e verificaremos se este está entre umas das distribuições GEV. Uma distribuição exponencial é caracterizada pela seguinte função de distribuição (c.d.f):
\[\begin{equation*}
F(x)=1-e^{- \beta x}, \beta > 0 \text{ e } x \geq 0
\end{equation*}\]
Se escolhermos as sequências \(c_n=1/\beta\) e \(d_n=\ln n /\beta\) podemos substituir diretamente na equação e calcular \(H(x)\).
\[\begin{equation*}
F^n \left(c_nx+d_n \right)=\left(1-\frac{1}{n}e^{-x} \right)^n
\end{equation*}\]
\[\begin{equation*}
\lim_{n \rightarrow \infty} \left(1-\frac{1}{n}e^{-x} \right)^n = H(x)
\end{equation*}\]
Fazendo uma simples substituição de variáveis, \(i=-e^{-x}\), então:
\[\begin{equation*}
H(x)=\lim_{n \rightarrow \infty}\left(1+\frac{i}{n} \right)^n
\end{equation*}\]
Que é o limite fundamental \(e^i\), o qual substituindo novamente \(i\) temos:
\[\begin{equation*}
H(x)=exp\left(-e^{-x}\right)=H_0(x), \text{Distribuição Gumbel}
\end{equation*}\]
Ou seja, a distribuição exponencial pertence ao \(MDA\) da distribuição Gumbel, a qual por sua vez é um dos casos particulares da GEV quando \(\xi=0\).
Via de regra não necessitamos calcular a qual \(MDA\) pertencem nossas distribuições, bastando saber que basicamente todas as distribuições contínuas de utilidade prática estão contidas em \(MDA(H_\xi)\) para algum valor de \(\xi\).
Excessos acima de um limiar
O método conhecido como POT, para calcular a função de distribuição dos valores que excedem um determinado limiar de um conjunto de dados vem sendo empregado no mundo financeiro para ajustar as caudas das distribuições de retornos, ou perdas, dos ativos. Este método é preferido a teoria clássica de valores extremos (e.g. máximos em bloco), pois, desperdiça uma quantidade menor de dados da série original. Qualquer valor que exceda o limiar pré-determinado é considerado na distribuição dos excessos. Esta distribuição dos valores da série que estão acima de um determinado limiar u é definida como:
Definição 3 (Distribuição dos excessos) Seja X uma variável aleatória com função de distribuição c.d.f F. A distribuição dos excessos sobre um limiar u tem a seguinte função de distribuição:
\[\begin{equation}
F_u(x)=P(X-u \leq x | X > u)=\frac{F(x+u)-F(u)}{1-F(u)}
\tag{3}
\end{equation}\]
para \(0 \leq x < x_F-u\), onde \(x_F \leq \infty\) é o limite direito da distribuição F.
Ou seja, a função distribuição dos excessos sobre um limiar u é a probabilidade condicional que um valor X retirado dos dados subtraído de u (o excesso) seja menor que um dado quantil x, sabendo-se que X é maior que u. Uma importante distribuição que surge na modelagem dos excessos sobre um limiar é a distribuição de pareto gereralizada – GPD, que segue.
Definição 4 (Distribuição de Pareto Generalizada) É definida por sua função de distribuição:
\[\begin{equation}
G_{\xi,\beta(u)}(X) =
\begin{cases}
1- \left(1+ \frac{\xi x}{\beta(u)} \right)^{-\frac{1}{\xi}}, & \xi \neq 0,\\
1-exp\left(-\frac{x}{\beta(u)}\right), & \xi = 0,\\
\end{cases}
\tag{4}
\end{equation}\]
onde \(\beta > 0\), e \(x\geq 0\) quando \(\xi \geq 0\) ou \(0 \leq x \leq -\beta / \xi\) quando \(\xi < 0\).
Os parâmetros \(\xi\) e \(\beta\) são conhecidos respectivamente como parâmetros de forma e escala da distribuição. Na figura 1 abaixo, são mostradas três parametrizações para a função de distribuição acumulada (c.d.f) e para a densidade de probabilidades (p.d.f) de GPD com parâmetro \(\xi\) iguais a -0,5, 0 e 0,5 enquanto que o parâmetro de escala \(\beta\) é mantido constante e igual a 1. Perceba como para \(\xi <0\) a p.d.f tem um limite direito que é dado por \(-\beta / \xi\) a partir do qual os valores de \(g(x)\) são zero.
A distribuição de Pareto generalizada tem papel fundamental na teoria de valor extremo em função do teorema de Pickands-Balkema-de Haan (Pickands (1975) e Balkema and Haan (1974)) conforme abaixo:
Teorema 2 (Pickands-Balkema-de Haan) Pode ser encontrada uma função \(\beta(u)\) tal que:
\[\begin{equation*}
\lim\limits_{u \rightarrow x_F} \; \sup\limits_{0\leq x <x_F – u} |F_u(x)-G_{\xi, \beta(u)}(x)| = 0
\end{equation*}\]
se e somente se \(F\in MDA(H_\xi)\) para \(\xi \in \mathbb{R}\).
O que este teorema nos diz é que para distribuições as quais os máximos em bloco normalizados convergem para uma GEV (na forma da equação (2)), então a distribuição dos excessos acima de um limiar destas mesmas distribuições convergem para uma GPD, dado um valor de limiar u adequado. Podemos fazer então a seguinte suposição:
Suposição 1: Seja F a distribuição de perdas com limite direito \(x_F\), assuma que para um valor limiar alto o suficiente u nós temos que \(F_u (x)=G_{\xi,\beta} (x)\), onde \(F_u (x)\) denota a distribuição dos excessos de x em relação ao valor de limiar u, para \(0 \leq x < x_F-u\), \(\xi \in \mathbb{R}\) e \(\beta > 0\).
Esta é uma suposição, uma vez que a distribuição dos excessos não segue exatamente uma GPD, mas apenas tende a esta distribuição dado um limiar u alto e uma amostra de dados grande o suficiente.
Dada a parametrização de uma GPD, é interessante sabermos o valor esperado desta distribuição, uma vez que esta medida de valor central nos fornece importante informação sobre a quantidade de risco que estamos buscando medir, assim como a informação de que a própria distribuição foi ajustada aos dados de forma satisfatória, como será demonstrado adiante.
O valor esperado de uma variável aleatória não negativa pode ser computado através da integral de sua cauda, \(P(X>x) = 1-P(X \leq x)\). A cauda da GPD é, para \(\xi \neq 0\), \(\left(1+\xi x / \beta(u) \right)^{-1/ \xi}\)
Bastando, portanto, integrar em relação a \(x\) sobre o domínio deste, que é de \(0\) a \(\infty\).
\[\begin{equation*}
\displaystyle\int\limits_{0}^{\infty} \left(1+ \xi x /\beta(u) \right)^{-1/\xi} dx
\end{equation*}\]
Desta forma, o valor esperado de uma GPD \(G_{\xi,\beta(u)} (X)\), ou seja, sua média, converge para valores de \(\xi<1\) e é dado pela seguinte equação:
\[\begin{equation}
E\left[G_{\xi,\beta(u)} (X) \right]=\frac{\beta(u)}{1-\xi}
\tag{5}
\end{equation}\]
Definição 5 (Função média dos excessos) A função média dos execessos de uma variável aleatória X com média finita é dada por:
\[\begin{equation}
e(u)=E\left(X-u | X > u\right)
\tag{6}
\end{equation}\]
Ou seja, a equação (6) representa o valor esperado da função de distribuição dos excessos dada pela Definição 3. Ela representa a média de \(F_u\) como uma função do limiar u. Esta função por vezes também é conhecida como função média de vida residual (mean residual life function), sendo encontrada esta denominação em alguns pacotes de software estatísticos.
Para uma variável distribuída na forma de uma GPD, o parâmetro de escala é uma função linear em u dado por \(\beta(u)=\beta + \xi u\), Teorema 3.4.13(e) em Embrechts, Klüppelberg, and Mikosch (1997). Utilizando-se deste fato e da equação (5) chegamos ao cálculo da função média dos excessos para uma GPD, dada por:
\[\begin{equation}
e(u)=\frac{\beta+\xi u}{1-\xi}
\tag{7}
\end{equation}\]
onde \(0 \leq u < \infty\) se \(0 \leq \xi <1\) e \(0 \leq u \leq -\beta / \xi\) se \(\xi < 0\). É possível observar que de fato a função média dos excessos em uma GPD é linear em u. Esta é uma característica importante de uma GPD e que nos auxilia a escolher um valor adequado do limiar u de tal forma que a Suposição feita anteriormente faça sentido.
Assim, quando estamos analisando uma determinada distribuição de perdas F e desejamos ajustar a cauda desta distribuição, ou seja, as perdas acima de um dado valor limiar u a uma GPD \(G_{\xi, \beta}(x)\) precisamos primeiramente determinar um valor adequado de u de modo que a suposição \(F_u(x)\rightarrow G_{\xi, \beta}(x)\) seja válida. Um método frequentemente utilizado é o gráfico da função média dos excessos com relação a u. Analisando este gráfico, escolhemos o menor valor de u para o qual a partir deste ponto a relação \(e(u) \text{ vs } u\) torna-se linear.
Desejamos o menor valor de u para o qual a relação é linear pois, mesmo o método POT implica em grande perda de dados da série temporal, já que apenas os valores acima deste limiar são utilizados para fazer a estimação dos parâmetros \(\xi\) e \(\beta\) da GPD. Portanto, existe um trade-off na escolha do valor limiar u, escolhendo um valor muito baixo termos uma boa quantidade de dados para estimar os parâmetros da GPD, mas a própria distribuição resultante não será GPD, uma vez que não estaremos trabalhando na região onde a relação \(e(u) \text{ vs } u\) é linear. Por outro lado, um valor limiar muito alto nos impõe o custo de trabalhar com poucos dados para fazer a estimação dos parâmetros da distribuição e por conseguinte, os erros padrões dessas estimativas serão elevados.
Lema 1 Sob a Suposição 1 segue que \(F_v (x)=G_{\xi,\beta+\xi(v-u)} (x)\) para qualquer valor limiar \(v \geq u\).
Logo, a distribuição dos excessos sobre limiares mais altos que u, também segue uma GPD com o mesmo parâmetro de forma \(\xi\) e parâmetro de escala que cresce linearmente com este limiar mais alto v. Se \(\xi < 1\), a média desta nova GPD converge e é dada por:
\[\begin{equation}
e(v)=\frac{\beta+\xi(v-u)}{1-\xi}=\frac{\xi v}{1- \xi}+ \frac{\beta-\xi u}{1-\xi}
\tag{8}
\end{equation}\]
Esta é a função média dos excessos sobre limiares mais altos, e está definida para \(u \leq v < \infty\) se \(0 \leq \xi < 1\) e, \(u \leq v \leq u-\beta / \xi\) se \(\xi < 0\).
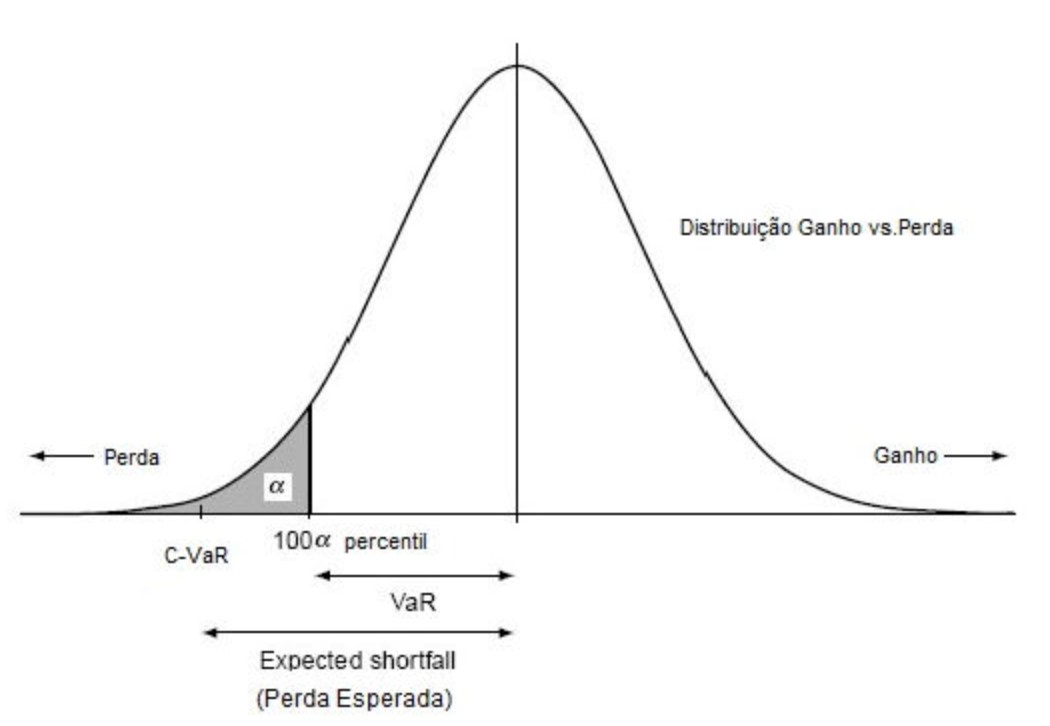
Esta função é muito útil para calcularmos o \(ES_\alpha\) (expected shortfall), considerando que \(VaR_\alpha\) nada mais é que um quantil superior ao limiar \(u\) escolhido.
Modelando caudas e medidas de risco associadas
Através da modelagem da cauda da distribuição F de perdas por uma GPD, como feito na seção anterior, é possível calcularmos as medidas de riscos \(VaR_\alpha \text{ e } ES_\alpha\) para esta distribuição de perdas em função dos parâmetros da GPD estimada e também fazendo uso da distribuição empírica de F.
Sob a Suposição 1 nós temos que a cauda da distribuição F, \(\bar{F}(x)\), para \(x \geq u\) é dada por:
\[\begin{align}
\bar{F}(x) & = P(X>u)P(X>x|X>u) \nonumber \\
& = \bar{F}(u) P(X-u>x-u|X>u) \nonumber \\
& = \bar{F}(u)\bar{F}_u(x-u) \nonumber \\
& = \bar{F}(u)\left(1+\xi \frac{x-u}{\beta}\right)^{-1/\xi}
\tag{9}
\end{align}\]
Da qual se soubéssemos exatamente a distribuição F teríamos um modelo analítico para as probabilidades de perdas na cauda da distribuição. Aqui \(x\) são os valores a serem observados das perdas, e portanto \(x-u\) são as perdas em excesso ao limiar.
O que fizemos através da equação (9) foi efetivamente separar a distribuição F, ou melhor, sua cauda, em duas partes. A primeira parte, para valores menores que u, não foi modelado analiticamente e portanto utilizamos a distribuição empírica das perdas, aqui representada por sua cauda \(\bar{F}(u)\), que nada mais é que o número observado de excessos de u sobre o número total de observações da amostra.
A segunda parte é justamente a modelagem através de uma GPD com parâmetros \(\xi \text{ e } \beta\) dado o limiar u. Por esta modelagem paramétrica podemos conhecer as probabilidades de cauda para valores de x maiores que u.
O quantil \(\alpha\) é a inversa da função distribuição e nos retorna o valor para o qual um percentual \(\alpha\) de observações da amostra é menor ou igual. Assim sendo, \(VaR_\alpha\) nada mais é que um quantil alto para o qual determinamos que \(\alpha \%\) das perdas devem ser menores ou iguais a este valor.
Como a equação (9) fornece a probabilidade de cauda, então esta é igual a \(1- \alpha\) para um valor de \(\alpha \geq F(u)\). Fazendo \(\bar{F}(x)=1-\alpha\) na equação (9) o valor de x representará \(VaR_\alpha\) e nos basta manipular esta equação até isolarmos \(VaR_\alpha\) como função de \(\bar{F}(u), \alpha \text{ e dos parâmetros da GPD } \xi \text{ e } \beta\). Que nos garante a equação abaixo:
\[\begin{equation}
VaR_\alpha = q_\alpha(F) = u+\frac{\beta}{\xi}\left[ \left( \frac{1-\alpha}{\bar{F}(u)}\right)^{-\xi}-1 \right]
\tag{10}
\end{equation}\]
A medida \(ES_\alpha\) pode ser entendida como a média das perdas que excedem o valor dado por \(VaR_\alpha\). Como o próprio \(VaR_\alpha\) é um quantil acima do valor de limiar u, \(ES_\alpha\) é dado pelo valor do \(VaR_\alpha\) somado a função média dos excessos dada pela equação (8) fazendo \(v = VaR_\alpha\). Esta média é convergente para valores de \(\xi < 1\) conforme já demonstrado. Ou seja, \(ES_\alpha=VaR_\alpha + e(VaR_\alpha)\). A qual nos rende de forma mais geral:
\[\begin{equation}
ES_\alpha = \frac{VaR_\alpha}{1-\xi}+\frac{\beta-\xi u}{1-\xi}
\tag{11}
\end{equation}\]
Portanto, ambas medidas de risco \(VaR_\alpha\) e \(ES_\alpha\), para distribuições de perdas que tiveram suas caudas modeladas através de uma GPD da forma \(G_{\xi, \beta(u)}\) com \(\xi <1 \text{ e } \beta > 0\), podem ser calculadas respectivamente através das equações dadas em (10) e (11). As estimativas destas medidas de risco serão encontradas através das estimativas dos parâmetros da GPD, assim como do limiar utilizado e de uma medida empírica de \(\bar{F}(u)\) que será o número de excessos verificados sobre o total de amostras. É claro que, ao adotarmos esta estimativa para \(\bar{F}(u)\) estamos implicitamente supondo que o número de amostras na série de perdas é significativa, assim como o número de excessos verificados. Daí a importância de se utilizar um valor u adequado, conforme explicitado na seção anterior.
As estimativas de medidas de risco desenvolvidas nesta seção se qualificam como medidas incondicionais, no sentido que elas não dependem do estado atual das coisas, mas sim de todo o histórico de eventos de forma uniforme. Em outras palavras, \(VaR_\alpha \text{ e } ES_\alpha\) derivados a partir das equações (10) e (11) são medidas históricas de risco associado ao ativo em análise e não levam em consideração se nos eventos mais recentes a volatilidade das perdas pode ser diferente do valor histórico.
De fato, uma das características marcantes das perdas (ou retornos, como o leitor preferir) dos ativos financeiros é o chamado clustering de volatilidade, onde grandes volatilidades (retornos positivos ou negativos) têm tendência a ficarem próximas ao longo da linha temporal. Em geral estas aglomerações de volatilidades surgem a partir da autocorrelação destas, ou seja, a volatilidade em um período t é dependente das volatilidades verificadas em períodos anteriores. Um modelo bastante encontrado na literatura que busca modelar estas dependências é o modelo GARCH e suas variantes.
Assim, ao passo que as estimativas de risco desenvolvidas nesta seção são valiosas para prazos mais longos, ainda é necessário desenvolver um modelo que lide com o fato das autocorrelações de volatilidades e portanto, que nossa variável aleatória não é independente e igualmente distribuída ao longo do tempo. O modelo proposto por McNeil and Frey (2000) pode ser utilizado para encontrar as medidas de risco \(VaR_\alpha\) e \(ES_\alpha\) condicionais que desejamos, ainda dentro da metodologia de peaks over treshold.
Medidas condicionais de risco
Ativos financeiros possuem características de autocorrelação, senão em seus retornos propriamente ditos, ao menos em suas volatilidades ou variações absolutas. Ou seja, dada uma grande variação no momento t é de se esperar novamente uma grande variação, não necessariamente na mesma direção daquela anterior, para o momento t+1 e posteriores. Desta forma, medidas de risco incondicionais, conforme aquelas derivadas na seção de medidas de risco podem ser adequadas somente para horizontes temporais mais longos, pois implicitamente tomam em consideração os fatos mais recentes com o mesmo valor de predição que fatos mais longínquos.
Também já foi bastante estudado e mostrado no artigo anterior que modelos que levem em conta riscos condicionais ao incorporarem as autocorrelações nas volatilidades, levam a resultados de testes melhores. Assim, nesta seção trabalharemos com o modelo proposto por McNeil and Frey (2000) os quais fazem uma adequação dos retornos dos ativos a um modelo GARCH e posteriormente tratam os erros desta modelagem como iid e portanto, a metodologia de POT e ajuste de uma GPD pode ser feito. Este modelo pode ser entendido como um modelo condicional para medidas de risco pois, efetivamente, é levado em conta o estado atual da previsão para a média e principalmente para a volatilidade ao se calcular o VaR. Desta forma a medida responde rapidamente às variações nos humores do mercado e pode sinalizar de forma ágil uma inadequação de capital reservado pela instituição financeira.
Além desta vantagem de cunho prático, a técnica possui uma atratividade teórica. O método POT deve ser aplicado a séries iid que sabidamente não é o caso de perdas de ativos financeiros. Ao se utilizar a técnica POT nos resíduos padronizados de um modelo GARCH o que se está realizando é uma pré-filtragem destas perdas, de forma a obter resíduos padronizados que sejam iid e portanto, aplicável a teoria de valor extremo.
Primeiramente vamos estabelecer um modelo GARCH para as perdas do ativo subjacente. Se denotarmos \(L_t\) como sendo a perda observada no período t, \(\mu_t\) e \(\sigma_t\) são respectivamente a média e o desvio padrão condicionais e mensuráveis através do conjunto de informações disponíveis em t-1 e seja \(Z_t\) inovações iid com média zero e desvio padrão unitário, então temos que:
\[\begin{equation}
L_t=\mu_t+\sigma_t Z_t
\tag{12}
\end{equation}\]
Seja \(F_L(l)\) a distribuição marginal de \(L_t\), então \(F_{L_{t+1}} | \mathcal{G}_t(l)\) é a distribuição preditiva da perda para o próximo período, onde \(\mathcal{G}_t\) é o conjunto de informações disponíveis no período t, incluindo-o. Portanto, para o cálculo das medidas condicionais de risco estamos interessados em um quantil \(\alpha\) na cauda de \(F_{L_{t+1} | \mathcal{G}_t}(l)\). Este quantil \(\alpha\), que será o nosso \(VaR_\alpha\), é o ínfimo l tal que o valor da distribuição preditiva seja maior ou igual a \(\alpha\). Ao passo que o valor condicional do ES será o valor esperado das perdas previstas que sejam maiores que VaR para o mesmo intervalo de confiança. Ou seja:
\[\begin{align}
VaR_\alpha^t=&\inf\{l \in \mathbb{R}: F_{L_{t+1} | \mathcal{G}_t}(l) \geq \alpha\}, \\
ES_\alpha^t=&E[L_{t+1} | L_{t+1} > VaR_\alpha^t]
\end{align}\]
Considerando que nossa distribuição de perdas é dada pela equação (12) e sabendo das propriedades de variáveis aleatórias e do operador de expectância, as equações dadas acima subsumem a:
\[\begin{align}
VaR_\alpha^t=&\mu_{t+1}+\sigma_{t+1}z_\alpha, \tag{13} \\
ES_\alpha^t=&\mu_{t+1}+\sigma_{t+1}E[Z | Z>z_\alpha] \tag{14}
\end{align}\]
onde \(z_\alpha\) é o quantil \(\alpha\) das inovações Z.
Agora nos falta escolher um processo que modele nossa série temporal dada em (12), ou seja, precisamos especificar o comportamento de \(\mu_t\) e \(\sigma_t\). Por suposição do modelo, especificamos que o comportamento destas variáveis é dependente de acontecimentos passados, contidos no conjunto de informações \(\mathcal{G}_{t-1}\) . Dentre os diversos modelos já propostos para estimar médias e volatilidades condicionais, está o simples porém efetivo modelo GARCH(1,1) para a volatilidade condicional e o modelo AR(1) para a média condicional. Uma extensão destes modelos básicos para outros mais complexos pode ser facilmente obtida e é vasta na literatura, como exemplo modelos GARCH-M, Treshold GARCH, EGARCH, etc. para volatilidades condicionais e um modelo do tipo ARMA para a média.
Como critérios para a escolha deste modelo de filtro no primeiro estágio, deseja-se que as inovações \(Z_t\), através de suas realizações na forma dos resíduos padronizados estimados no modelo possuam 2 características, ausência de autocorrelação serial em seus valores e nos seus quadrados.
Neste artigo, visando aplicar a teoria do valor extremo para o cálculo das medidas condicionais de risco, não faremos maiores assunções acerca da distribuição das inovações, como por exemplo assumir uma determinada distribuição (e.g. Normal ou t de Student), mas está implícito que esta pertence ao MDA de uma GEV e portanto a distribuição de seus excessos sobre um limiar segue aproximadamente uma GPD.
Dadas estas considerações, o modelo adotado segue um formato em dois estágios para ser implementado, como segue.
Referências
Balkema, A A, and L de Haan. 1974. “Residual Life Time at Great Age.” The Annals of Probability 2 (5): 792–804. doi:10.1214/aop/1176996548.
Embrechts, P, C Klüppelberg, and T Mikosch. 1997. Modelling Extremal Events for Insurance and Finance. Springer.
Fisher, R A, and L H C Tippett. 1928. “Limiting forms of the frequency distribution of the largest or smallest member of a sample.” Proceedings of the Cambridge Philosophical Society 24: 180–90.
Gnedenko, B V. 1941. “Limit theorems for the maximal term of a variational series.” Comptes Rendus (Doklady) de L’Académie Des Sciences de L’URSS 32: 7–9.
———. 1943. “Sur la distribution limite du terme maximum d’une série aléatoire.” Annals of Mathematics 44: 423–53.
McNeil, Alexander J, and Rüdiger Frey. 2000. “Estimation of tail-related risk measures for heteroscedastic financial time series: an extreme value approach.” Journal of Empirical Finance 7 (3-4): 271–300. doi:10.1016/s0927-5398(00)00012-8.
Pickands, James. 1975. “Statistical Inference Using Extreme Order Statistics.” Annals of Statistics 3: 119–31. doi:10.1214/aos/1176343003.