Ao final de janeiro de 2021, os noticiários e redes sociais passaram a ficar tomadas de comentários acerca do aumento exponencial no preço de várias ações no mercado americano, com destaque para a GameStop, cujo ticker na New York Stock Exchange é GME.
O motivo? Um Short Squeeze realizado por usuários de um grupo do Reddit chamado WallStreetBets, um grande grupo de investidores pessoa física, que no intuito de “dar o troco” em fundos de investimento – que supostamente entram short em ativos no intuito de ganhar dinheiro sobre investidores pessoa física – realizaram transações com ações e opções gerando um efeito bola de neve que fez com que os preços subissem a patamares estratosféricos.
Mas como é possível realizar tais procedimentos? E por que essa subida foi tão abrupta? Essas e muitas outras questões acerca do Short Squeeze e suas dinâmicas subjacentes serão respondidas neste artigo.
Por que a GameStop?
A primeira pergunta é simples, mas é a mais importante para responder sobre a dimensão que teve o caso.
A GameStop é uma empresa varejista de video-games e entretenimento fundada em 1984. Ela teve seu IPO (initial public offering) em 2002, e desde então sua maior fonte de receita tem sido em eletrônicos e jogos físicos, operando mais de 3500 lojas nos Estados Unidos, Canadá, Austrália, Nova Zelândia e Europa.
A empresa começou a ter dificuldades com a mudança de preferência dos consumidores, que passaram a perder o interesse em jogos físicos, tendo em vista que serviços online como Xbox Live, Playstation Network, Nintendo eShop e Steam, tiveram muita adesão no mercado e ofereciam jogos digitais cuja compra e download podia ser feita no conforto de casa.
Em 2017 a empresa reportou uma queda de 16,4% nas vendas durante os feriados de final de ano. Os anos seguintes se sucederam com o fechamento de lojas, queda no preço das ações, piores resultados e pouca adesão de seu sistema de vendas online, até 2020, quando a pandemia do Covid-19 forçou o fechamento de suas 3500 lojas por aproximadamente três meses.
As vendas digitais cresceram muito, mas a empresa passou a ser criticada pela resposta à pandemia, com empregados e usuários de redes sociais acusando a companhia de colocar os negócios à frente da segurança de seus funcionários e consumidores.
Durante o período de seu declínio, fundos de investimento – assim como investidores pessoa física, mas de maneira menos expressiva – montaram posições vendidas (short) na ação chegando a um ponto onde havia 150% de short interest. A posição short racionalizava-se na ideia de um declínio no valor da ação tendo em vista piores resultados e participação da empresa no mercado. Essa taxa de mais de 100% permitiu o movimento explosivo do short squeeze e logo explicaremos o porquê.
O que é um Short Squeeze?
Um Short Squeeze ocorre quando o preço de uma ação sobe de maneira rápida e acentuada, o que faz com que investidores que apostam na queda do ativo e estejam com posições short em aberto comprem o ativo para evitar perdas. Essas compras aumentam a pressão de compra no ativo e mais uma vez levam a uma subida no preço.
A ideia vem de que os investidores são forçados (ou apertados, na tradução literal) a zerar a sua posição vendida no ativo, geralmente em uma posição na qual já estão perdendo dinheiro e querem limitar as perdas.
Para quem tem familiaridade com o mercado financeiro a ideia de que uma posição short é muito mais arriscada que uma posição long (comprada) já é intuitiva, mas caso o leitor não tenha tanta familiaridade, sua análise é simples: quando o investidor compra uma ação, ele está assumindo um risco com seu capital; em uma posição comprada, o pior risco para este investidor é perder todo seu dinheiro em alguma situação extrema (falência, desastres naturais) que façam o preço da ação cair a zero; já em uma posição vendida o investidor está alugando o ativo para comprá-lo novamente em um período posterior, assumindo o compromisso dessa compra. Num aumento substancial no preço da ação, o prejuízo da posição vendida é ilimitado (pode ser maior que o valor total do capital investido), se uma ação sobe mais de 100% a posição já está perdendo mais capital do que o investidor possui. Em fatores gerais, enquanto um investidor com uma posição comprada comum pode apenas perder todo seu dinheiro, uma posição vendida pode causar, além da perda total, uma dívida adicional sobre o capital investido.
Tendo em vista essa informação, cada vez que o ativo sobe, torna-se crucial para o investidor encerrar sua posição vendida, o qual irá entrar no mercado com uma posição compradora, que força novamente o preço para cima, o que leva o investidor seguinte a encerrar a posição, formando um efeito bola de neve.
Como é possível realizar tais procedimentos?
A ideia mais simples e intuitiva de realizar um short squeeze seria comprar a posição à vista, não? Na verdade, não. No Brasil, dias depois de noticiados os acontecimentos com a GameStop, investidores se organizaram em um grupo de Telegram, juntando mais de 40 mil membros, com o objetivo de recriar o movimento no papel IRBR3, ou IRB Brasil RE, uma resseguradora brasileira. Percebeu-se no mercado no dia seguinte inúmeras compras do papel à vista, fazendo ele fechar com um aumento de 18%, realmente significativo, mas que não se manteve.
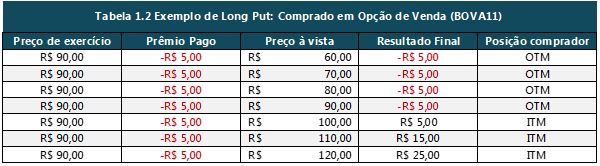
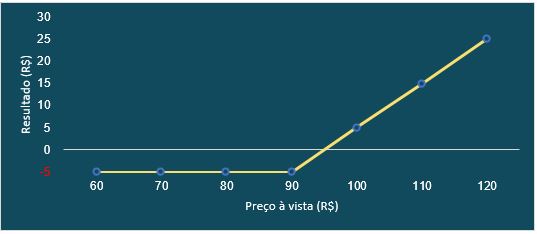
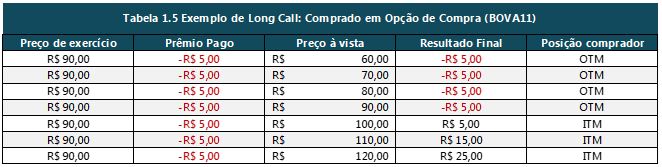
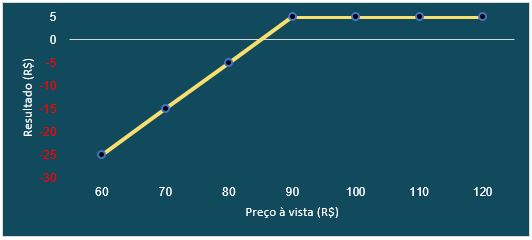
Para realizar um movimento desses com o próprio ativo, seria necessário um volume enorme de transações ou a escolha de uma ação pouco negociada, cujo preço é mais suscetível a menores volumes. As alternativas envolvem a negociação de opções e para entendermos a dinâmica que elas oferecem recomendamos o artigo de Introdução ao Mercado de Opções. Caso o leitor já tenha familiaridade e entenda o funcionamento das opções de compra e venda, assim como já conheça as definições de ITM (In The Money), ATM (At The Money) e OTM (Out of The Money), iremos nos direcionar para a explicação de novos conceitos necessários para a criação desses movimentos.
As Letras Gregas
As Gregas são medidas de diferentes dimensões do risco em uma posição em opções, sendo que o objetivo do trader é gerenciar as gregas de modo que todos os riscos sejam aceitáveis. Neste artigo não entraremos a fundo em todas as gregas, apenas no Delta e Gama, as quais são de extrema importância para o caso da GameStop.
Delta
O delta de uma opção (Δ) representa a primeira derivada da função de apreçamento da opção em relação ao preço do ativo subjacente, ou seja, ela representa a taxa de mudança no preço da opção, quando há mudança no preço do ativo. Um delta de 0,4 demonstra que quando o preço da ação subjacente muda em uma pequena quantia, o preço da opção muda em 40% dessa quantia. Essa grega também é interpretada como a inclinação da curva que relaciona o preço da opção com o preço do ativo subjacente (ou seja, a derivada).
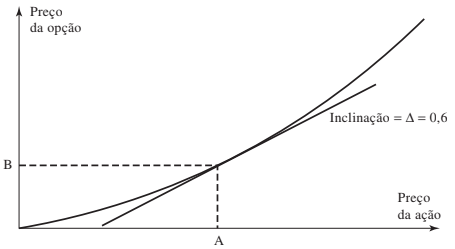
Figura 1: Cálculo do Delta
Uma maneira de fazer hedge (proteção) de uma posição de opções de compra emitidas (posição vendida) é comprando Δ vezes o número de ações referentes a essa posição em opções. Por exemplo, se o investidor vendeu uma posição referente a 4000 ações cuja opção possui delta 0,4, sua posição fica protegida quando ele compra 0,4*4000 = 1600 ações. Nesse caso, para qualquer movimento, um ganho na posição vendida vai compensar a perda na posição comprada e vice-versa. Ao montar essa proteção o investidor possui o que chamamos de portfólio Delta Neutro.
Até aqui o delta parece simples assim como sua proteção, apesar disso, ele não é uma variável constante, o que torna a posição do trader neutra apenas por um período relativamente curto, criando a necessidade de rebalanceamento do portfólio.
Gama
O gama (Γ) de um portfólio é interpretado como a segunda derivada da função de apreçamento da opção em relação ao preço do ativo subjacente, ou seja, ela é a taxa de mudança do delta do portfólio com relação ao preço do ativo subjacente.
Se o gama é pequeno, o delta muda lentamente e os ajustes para manter o portfólio delta neutro precisam ser realizados relativamente poucas vezes. Contudo, se o gama é altamente positivo, o delta se torna bastante sensível ao preço do ativo subjacente. Quando o gama é “grande”, o portfólio diminui de valor se não há mudança no preço da ação, mas aumenta de valor se há uma grande mudança positiva ou negativa.
Desse modo, opções no dinheiro (ATM) são as com maior gama, posição na qual o delta está perto da metade de seus valores possíveis (próximo de 0,5 para calls e -0,5 para puts), pode-se observar também que quando uma opção está muito fora do dinheiro seu delta é próximo de zero e muda de maneira lenta com relação ao preço do ativo subjacente. Quando uma opção está muito dentro do dinheiro, seu delta está próximo de 1 (-1 para puts), mas muda de maneira lenta com relação ao preço do ativo.
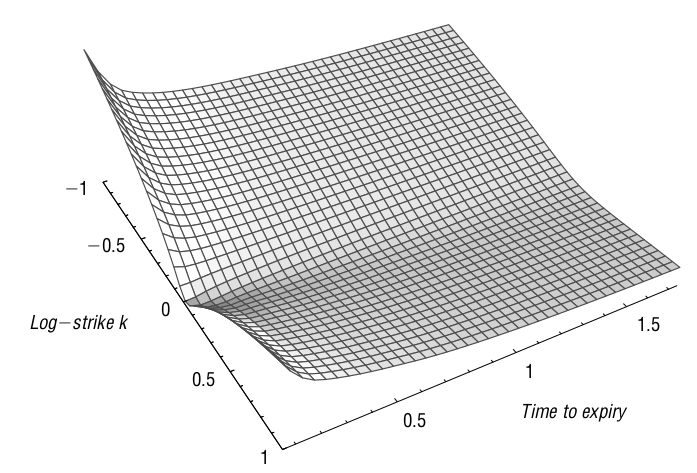
Outro fator que afeta o gama é o tempo, além de sua relação negativa com a outra grega Teta (mudança no valor do portfólio com relação à passagem do tempo), ao aproximar-se do vencimento da opção, o gama torna-se explosivo, como demonstrado no gráfico abaixo. Essa dinâmica permite que essa grega se torne um importante fator na execução de um short squeeze, na abordagem chamada Gamma Squeeze.

Figura 2: Gama contra strike e tempo
Market Makers
Os Market Makers (MMs), ou Formadores de Mercado, são pessoas jurídicas cadastradas em suas respectivas bolsas de valores que se comprometem a manter ofertas de compra e venda de forma regular e contínua durante a sessão de negociação, mantendo a liquidez de ativos, facilitando os negócios e mitigando movimentos artificiais nos preços.
Em geral, quem realiza essa função são bancos, corretoras e outras instituições financeiras. Essa função entrega ao investidor a garantia de conseguir vender seu ativo quando precise do dinheiro, permitindo que a transação ocorra a um preço justo do ativo, sem adicionar um prêmio pelo risco de liquidez.
Short Squeeze
A partir dos conceitos demonstrados, o leitor torna-se capaz de entender a dinâmica envolvida no short squeeze e todas as suas particularidades.
A utilização de opções para tal procedimento baseia-se na atuação dos market makers. Quando é aberta uma compra ou venda de opções, a chance é muito maior que esteja sendo realizada a operação com um market maker, o qual é responsável pela emissão ou aquisição das opções para manter a liquidez do mercado, do que com um investidor individual. Mas essa operação realizada pelos MMs também tem como objetivo gerar lucro (não necessariamente na posição em si, mas na taxa de juros recebida na montagem dela), então o preço negociado por eles está baseado em uma análise estatística baseada geralmente no modelo de Black-Scholes-Merton, o qual demonstra a posição que deve ser mantida pela instituição para que eles permaneçam com o delta neutro, assim como o gama permite descobrir quanto ela deve hedgear sua posição.
No caso da GameStop, os grandes volumes vendidos no ativo provenientes da visão pessimista, poderiam ser hedgeados na compra de opções OTM baratas, emitidas pelos MMs, representando a primeira pressão compradora no ativo. Outro movimento ocasionado pelos volumes short, é o stop-loss dos investidores, que consiste em comprar o ativo à vista para sair da posição, pressionando novamente o preço para cima.
Os investidores interessados no short squeeze, ao invés de comprarem opções ATM para forçar o gama dos MMs, começaram a comprar opções OTM com vencimento próximo, por serem muito mais baratas e com gama explosivo (Gamma Squeeze). Isso muda a dinâmica do gama nos cálculos dos market makers, os forçando a comprar mais do papel a vista para hedgear sua posição, neutralizando o gama.
O caso da GameStop, se tornou notícia mundial e foi realmente um ponto fora da curva, no momento que escrevo este artigo o preço da ação é negociado a cerca de 750% de seu valor antes do short squeeze mas a 40% de seu valor no pico do evento, apesar de estar a mais de um mês de seu acontecimento.
Por fim, um ponto importante trazido pela dinâmica de short squeeze é que da mesma forma que sua subida é abrupta e acentuada, sua queda se confirma. Observe que o gama é baseado na inclinação do delta, e quanto mais longe do strike, menor é o ajuste de hedge das posições, além disso, ao passo que as opções expiram ou seus contratos são executados, o market maker não é mais requerido de manter um hedge, tendo em vista que sua posição não existe. Não importa qual a dinâmica da inversão do movimento, os Gamma Squeezes não são eternos e seu movimento negativo pode ser pior que a subida inicial. Nesses cenários, a volatilidade é imensa, o que torna a previsibilidade quase impossível, por isso, se o investidor não tem pleno conhecimento e consciência da posição que está estabelecendo, a melhor escolha é observar e aprender, tendo em vista que muitos cenários são desastrosos para o capital investido nesses ativos.
Referências
HULL, J. C. Options, futures and other derivatives. 9th. ed. [S.l.]: Pearson, 2015.
Investopedia. Disponivel em: <https://www.investopedia.com/>. Acesso em: 04 Fevereiro 2021.
The Motley Fool. Disponivel em: <https://www.fool.com/>. Acesso em: mar. 2021.
GAMESTOP. Wikipedia. Disponivel em: <https://en.wikipedia.org/wiki/GameStop#GameStop’s_successful_years_(2004%E2%80%932016)>. Acesso em: 04 Fevereiro 2021.
HOUSTECKY, P. Option Gamma. Macroption. ISSN https://www.macroption.com/option-gamma/. Acesso em: 06 mar. 2021.
OPTION Gamma Explained: The Ultimate Guide. ProjectOption. Disponivel em: <https://www.projectoption.com/option-gamma-explained/>. Acesso em: 06 mar. 2021.