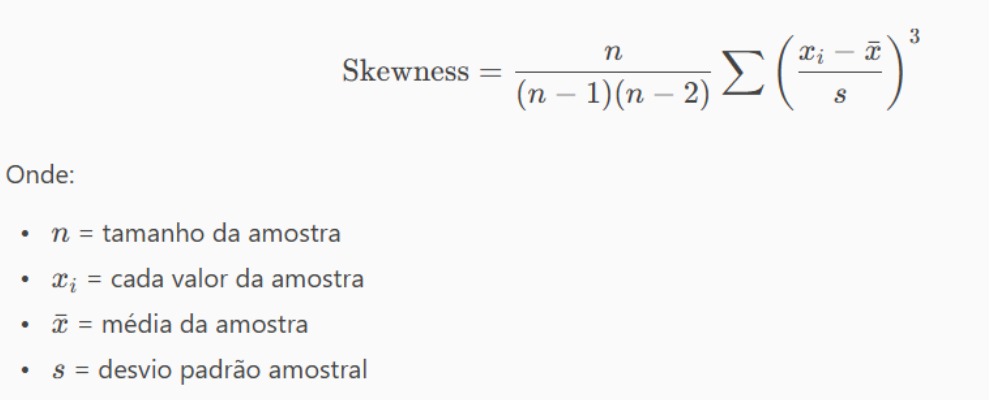É amplamente conhecido o fato de que instituições financeiras têm contabilidades diferentes de empresas tradicionais e, consequentemente, a análise financeira de seus demonstrativos também é diferente de uma análise de uma indústria ou de um comércio varejista. Margem EBITDA? ROIC? No caso dos bancos, essas métricas sequer existem, mas podemos utilizar, por exemplo, o tradicional ROE para metrificar o retorno da empresa.
No entanto, as instituições financeiras possuem outras diferenças no universo das finanças. Por exemplo, em uma situação hipotética em que um banco quer comparar a rentabilidade de uma operação de R$ 10 milhões a uma taxa CDI + 1,0% com uma operação de mesmo montante a uma taxa de CDI + 8,0%, qual seria mais rentável? À primeira vista, a resposta parece óbvia: a operação de CDI + 8,0% é muito mais rentável. Porém, podemos argumentar que essa segunda operação provavelmente é muito mais arriscada, dado que o tomador deve ter um perfil de crédito negativo para ser forçado a tomar empréstimo a uma taxa tão alta.
Além disso, bancos são instituições extremamente regulamentadas e, para cada operação de crédito que fazem, têm de imobilizar capital proporcional ao risco para cobrir suas possíveis perdas. Dessa forma, para alocar capital da maneira mais eficiente possível, a Bankers Trust criou nos anos 1970 o RAROC (Risk-Adjusted Return on Capital), que se tornou, entre muitas de suas variações como o RARORAC, uma das principais métricas para medir o retorno de operações de crédito e para gestão bancária como um todo.
Dessa forma, podemos comparar duas carteiras de perfis diferentes de forma justa. Por exemplo, um gerente de banco que administra uma carteira de empresas AAA com spread médio de 1,0% pode, em um primeiro momento, parecer gerar muito menos ROE que um gerente que administra uma carteira de clientes com empresas médias/pequenas com spread médio de 9,0%. No entanto, essa análise rasa desconsidera o capital que o banco tem de alocar para cobrir as perdas potenciais, ou seja, ao longo deste artigo vamos observar que o gerente com a carteira de risco consome muito mais capital da instituição financeira do que o gerente com a carteira de empresas AAA. Usualmente, se bem calibrado, o RAROC dos bancos tende a guardar relação com o ROE realizado.
Neste artigo, vamos entender a história, utilidade prática e o cálculo do RAROC.
A Basileia e a evolução da métrica RAROC
A utilização do indicador evoluiu com os Acordos de Basileia, um conjunto de recomendações internacionais conhecidos, principalmente, por traçar diretrizes sobre regulamentação bancária, como definições de capital mínimo que os bancos devem manter para absorver riscos. Segue um breve resumo sobre cada um dos três acordos:
Basileia I (1988): exigência de uma reserva de capital mínima de 8% sobre os ativos ponderados pelo risco;
Basileia II (2004): introduziu três pilares, envolvendo exigências de transparência, além de exigências de reservas de capital para riscos operacionais, de mercado e de crédito;
Basileia III (2011): criada em resposta à crise de 2008, busca conter o risco de propagação de crises financeiras, estabelecendo colchões de capital para tempos de crise, índices de liquidez a serem seguidos, entre outras regulamentações.
Dessa forma, para atender às exigências dos órgãos regulamentadores, foram criados sistemas cada vez mais sofisticados para administrar riscos.
Basileia na prática: o caso do Itaú Unibanco
Para ilustrar como esses conceitos se aplicam na prática, podemos observar os índices reportados pelo Itaú Unibanco, divulgados em seu relatório Pilar 3 no final de 2025. Eles revelam como um banco sistemicamente importante calibra suas reservas muito acima do mínimo regulatório.
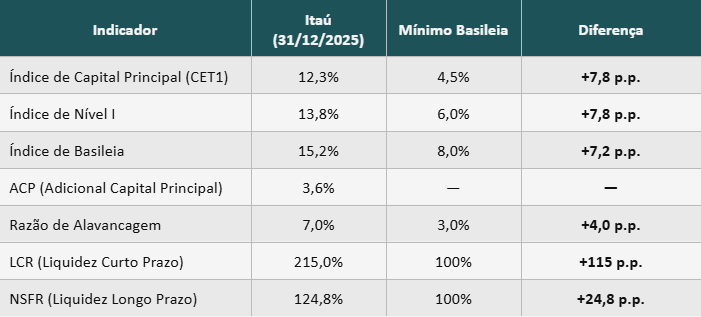
Índice de Capital Principal (CET1): capital de maior qualidade, composto por capital social de ações ordinárias integralizadas, reservas de lucros e sendo subtraído de ágio, ativos intangíveis e outros ajustes prudenciais. Para chegar ao índice, divide-se o capital principal pelos ativos ponderados pelo risco (pondera-se o valor dos títulos do banco pelo seu risco).
Índice de Nível 1: é o CET1 adicionado de capital complementar(no numerador), como letras financeiras perpétuas ou instrumentos que convertem em ações ou são extintos automaticamente se o CET1 cair abaixo de determinado gatilho. No caso do Itaú, seu Índice de Nível 1 está 1,5% acima do CET1 devido aos seus títulos de dívida perpétua.
Índice de Basileia: é o Índice de Nível 1 com a adição, principalmente, de letras financeiras subordinadas no numerador.
Adicional de Capital Principal (ACP): é a exigência adicional sobreposta aos mínimos de índice de capital, introduzida por Basileia III. No caso do Itaú, está no valor de 3,6% porque:
ACP de conservação (2,5%): fixo para todos os bancos. Caso o banco não consiga cumprir, sofre restrições para distribuir JCP, dividendos, bônus aos executivos e para recomprar ações;
ACP contracíclico (0,1%): variável de acordo com definição do Comitê de Estabilidade Financeira (Comef), atualmente estabelecido em 0% no Brasil. Os 0,1% vêm da exposição do Itaú à economia chilena;
ACP Sistêmico (1%): aplicável a bancos sistemicamente importantes, com o valor dependendo do seu tamanho.
Razão de Alavancagem: razão entre Índice de Nível 1 e ativos totais (sem ponderação).
Liquidity Coverage Ratio (LCR): índice de liquidez de curto prazo criado por Basileia III, é a razão entre ativos líquidos de alta qualidade e saídas líquidas de caixa estressadas nos últimos 30 dias (o regulador define pesos diferentes para diferentes tipos de funding, como depósito de varejo, atacado e captação interbancária). Esse indicador deve ser sempre, no mínimo, 100%.
Net Stable Funding Ratio (NSFR): indicador de liquidez com maior horizonte de tempo, dividindo as captações ponderadas pela estabilidade (capital próprio tem peso 100%, depósito de varejo tem peso menor) pelos recursos estáveis requeridos (caixa exige 0% de funding estável, empréstimos de longo prazo exigem 85%).
Como calcular o RAROC?
Para calcular o RAROC, precisamos antes estabelecer o significado de dois conceitos importantes: Lucro Econômico e Capital Econômico.
Lucro Econômico
O Lucro Econômico é um conceito com o qual muitos já estão familiarizados, sendo diferente do lucro contábil por considerar também os custos implícitos da empresa. Sendo assim, podemos calcular o lucro econômico da seguinte forma:
Lucro Econômico = Receita de Juros − Custo de Funding − Despesas Operacionais − Perda Esperada − Impostos
Poderíamos adicionar também receitas de serviços, por exemplo, em operações que envolvam o time de IB para estruturar uma operação, mas nosso objetivo não é se ater a esse tipo de detalhe. Observe também que a perda esperada é incluída na conta, o que significa que os bancos incluem pelo menos parte do risco no preço da operação.
Resumindo de forma simplificada cada termo da operação:
Receita de Juros: receita total do empréstimo concedido pelo banco. Por exemplo, se foi concedido um empréstimo de R$ 10 milhões a uma taxa de 20% a.a., a receita anual será de R$ 2 milhões;
Custo de Funding: custo para captar o crédito que o banco concedeu. Ou seja, se para captar esses mesmos R$ 10 milhões o banco pagou uma taxa de 14% a.a., o custo de funding será de R$ 1,4 milhão ao final do ano;
Despesas Operacionais e Impostos: Despesas operacionais podem incluir custos com infraestrutura, pessoal, tecnologia, entre outros. Como o banco costuma centralizar suas operações de backoffice para atender a diversas demandas, é difícil definir o custo operacional de uma operação de crédito;
Perda Esperada: é dada pela seguinte fórmula:
EL = PD × LGD × EAD
PD (Probability of Default): é a probabilidade de que o tomador não honre seu compromisso, sendo definida com base no rating da empresa. Atualmente, é comum que bancos tenham sistemas IRB (Internal Ratings-Based) avançados, sendo capazes de definir internamente o rating das empresas tomadoras com base nos dados de suas próprias carteiras. Para fins didáticos, usaremos uma taxa de default arbitrária em nossas simulações.
LGD (Loss Given Default): é a fração da exposição que o banco efetivamente perde quando o tomador entra em default, após todos os processos de recuperação, como execução de garantias e renegociações, sendo que LGD = 1 − Taxa de Recuperação.
A LGD pode variar de acordo com o tipo de garantia envolvida, sendo que a Basileia II incentiva que os bancos usem estimativas internas. Nesse caso, é interessante notar que no Brasil, onde há grande dificuldade de executar garantias, esse fator interfere na rentabilidade e, consequentemente, no custo de crédito.
EAD (Exposure at Default): nada mais é do que o valor total ao qual o banco está exposto no momento do default, ou seja, o saldo devedor. Vale destacar que, em linhas de crédito rotativo, o exposure at default tende a ser maior que o saldo atual, dado que o tomador tende a tomar mais dinheiro às vésperas de seu default, sendo um ponto sensível em aplicações práticas de mensuração de risco.
Capital Econômico
Já o Capital Econômico nada mais é do que o capital regulatório exigido dado o risco da operação. Mas que risco, se a perda esperada já foi incorporada no cálculo do Lucro Econômico? O risco que tratamos aqui é o risco da perda inesperada. Para explicar melhor, podemos definir a probabilidade de perdas por uma Distribuição de Poisson:
P(X = x) = (λˣ · e⁻ᵏ) / x!
Com base na distribuição de Poisson chegamos a um valor de perda esperada com base em nosso número esperado de defaults. Ao mesmo tempo, podemos usar a distribuição para estimar a perda em um cenário severo com um dado nível de confiança (99,99% no exemplo que iremos usar). O capital econômico é simplesmente o capital do banco usado para cobrir a diferença entre a perda esperada e as “perdas inesperadas” em cenários extremos e garantir a liquidez da instituição e a estabilidade do sistema financeiro.
É importante ressaltar as vantagens e desvantagens da distribuição de Poisson nesse caso. Como essa distribuição possui apenas um parâmetro (λ), representado aqui como número de defaults, ela acaba sendo fácil de calibrar e útil para fins didáticos. No entanto, ela assume que as variáveis são independentes e que sua variância é igual à média, subestimando a dispersão real. Dessa forma, tende a subestimar crises (onde a variância costuma ser maior que a média) e, além disso, costuma subestimar a cauda de forma consistente.
Embora a distribuição de Poisson seja útil para modelos didáticos, modelos profissionais têm graus consideravelmente maiores de complexidade.
Por fim, o cálculo do RAROC é feito ao se dividir o lucro econômico pelo capital econômico a ser investido em cada operação de crédito. Logo, a fórmula pode ser expressa da seguinte forma:
RAROC = (Margem Financeira − Perda Esperada − Despesas Operacionais – Impostos) / Capital Econômico
Lembrando que: A margem financeira é a receita financeira de juros subtraída pelo custo de funding.
Simulação de Cálculo de RAROC
Vamos observar o caso de um banco de rating AAA, com custo de funding de 14,65% e uma carteira de R$ 10 bilhões dividida em 1.000 empresas para quem ele emprestou.
Na tabela abaixo, temos de nosso banco hipotético, instituição AAA que calcula sua perda inesperada com uma taxa de 99,99% de confiança. Logo, paga uma taxa de 14,65% (equivalente a cerca de 100% do CDI, em um cenário de Selic a 14,75%).
O banco estima que, para sua carteira de 1.000 clientes, é esperado um número de 25 defaults, com uma LGD de 60%, ou seja, para cada operação perdida de R$ 10 milhões, espera-se perder um total de R$ 6 milhões. Considerando que há 25 defaults esperados, a perda esperada é de 25 × R$ 6.000.000 = R$ 150.000.000.
Agora, para garantir capital para assegurar perdas com uma probabilidade de 99,99%, precisamos verificar por meio da distribuição de Poisson, que construímos por meio de uma tabela no Excel, com a função DIST.POISSON():

Com isso, chegamos ao número de 65 inadimplentes, atingindo uma perda inesperada total de R$ 390 milhões, subtraindo esse valor da perda esperada, chegamos ao capital investido para viabilizar a carteira de crédito de R$ 10 bilhões.
Resumo dos parâmetros e resultado da simulação
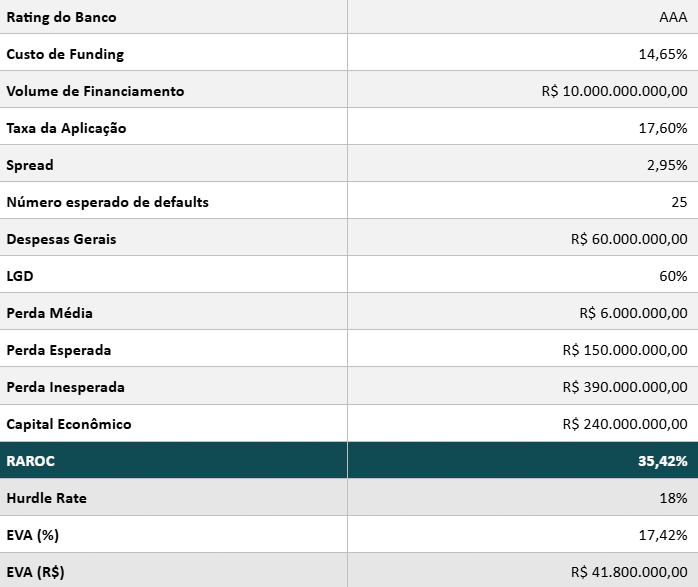
Aplicando a fórmula (Não consideramos impostos nas nossas premissas para efeitos de simplificação):
RAROC = (Margem Financeira − Perda Esperada − Despesas Operacionais) / Capital Econômico
RAROC = (2,95% × R$ 10.000.000.000 − R$ 150.000.000 − R$ 60.000.000) / R$ 240.000.000 = 35,42%
Análises de sensibilidade
Vamos observar o impacto de uma variação do LGD, custo de funding e do número esperado de dafaults na operação que acabamos de simular:
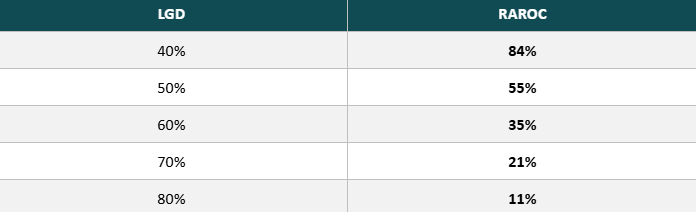
Variação do RAROC com a LGD (Loss Given Default)
Por meio de uma análise de sensibilidade do RAROC com base na variação da LGD, podemos observar um impacto relevante sobre a rentabilidade dos bancos. Essa observação demonstra o quanto uma melhora nas taxas de recuperação de créditos pode viabilizar spreads menores. Logo, garantias reais viabilizam spreads significativamente menores e, além disso, a segurança jurídica para executar garantias tende a reduzir spreads de maneira estrutural.
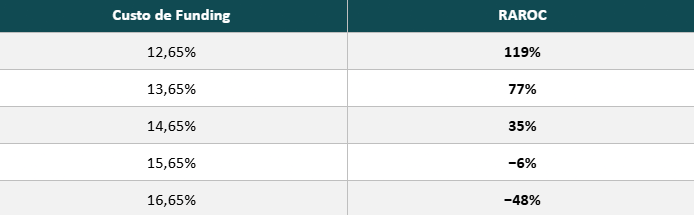
Variação do RAROC com o Custo de Funding
Bancos grandes costumam pagar taxas próximas a 100% do CDI; no entanto, bancos menores muitas vezes pagam taxas maiores em função de seu risco. Além disso, bancos AAA calculam sua perda inesperada com altas taxas de confiança (99,99%, por exemplo), enquanto bancos menores tendem a ser mais flexíveis, diminuindo a necessidade de investimento por operação (podem usar taxas de confiança de 99%, por exemplo).
No entanto, embora uma maior flexibilidade no cálculo da perda inesperada permita uma menor quantidade de capital investido, essa prática costuma aumentar o custo de funding da instituição, muitas vezes fazendo com que bancos de segunda linha percam competitividade em operações de menor risco, com clientes que exigem menores taxas dado seu alto grau de bancabilidade e estabilidade financeira.
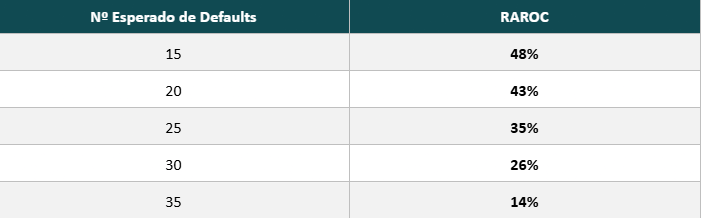
Variação do RAROC com o Número Esperado de Defaults
O número esperado de defaults é impactado pela qualidade de crédito da carteira de clientes. De forma geral, essa qualidade de crédito é atribuída por meio de sistemas de rating internos dos próprios bancos, que utilizam sua própria carteira para estimar o risco. Pela tabela, podemos observar que a piora na qualidade de crédito impacta o RAROC de forma não linear.
A relação PD × densidade de RWA no Itaú
O Itaú divulga, no Pilar 3, a relação entre intervalos de PD e a densidade de RWA (ativo ponderado pelo risco) para sua carteira de Agro.
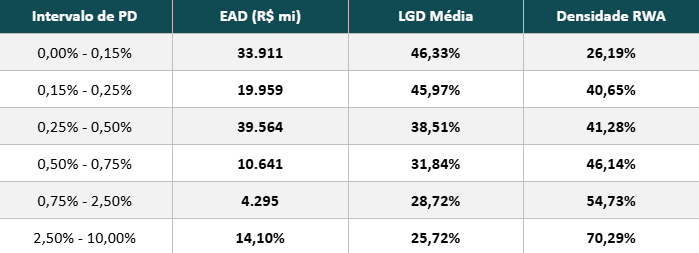
Note que a densidade de RWA alocado salta de 26,19% em clientes AAA até 70,29% em clientes mais arriscados, evidenciando quanto capital a mais um cliente com rating pior pode consumir, mesmo que o saldo devedor seja idêntico. Outro ponto interessante a se notar é a diminuição da LGD conforme aumenta a probabilidade de default do cliente, isso se deve ao fato de que, quanto pior o rating do tomador, mais garantias reais o banco costuma exigir.
Aplicações da métrica
O RAROC é uma métrica amplamente utilizada para tomada de decisões estratégicas no setor bancário, sendo utilizada tanto para aprovação de crédito quanto para alocação de capital.
Pricing de crédito
O RAROC é comumente utilizado para a precificação de crédito. Assim, o banco usa seu custo de capital próprio como ponto de partida para determinar o spread mínimo a ser cobrado pelo empréstimo. Podemos manipular a fórmula da seguinte maneira:
Spread Mínimo = (RAROC Desejado × Capital Econômico + Perda Esperada + Despesas Operacionais) / Saldo Devedor
No exemplo a seguir, considerando uma hurdle rate de 18%, podemos calcular o spread mínimo a ser cobrado e o valor econômico agregado em uma operação de crédito para uma instituição financeira que deseja um RAROC de 20%.
Spread Mínimo = (20% × 240.000 + 150.000 + 60.000) / 10.000.000 = 2,58%

Também podemos extrair o valor econômico adicionado da operação:
EVA = (RAROC − Hurdle Rate) × Capital Econômico
EVA = (20% − 18%) × R$ 240.000 = R$ 4800,00
Alocação de capital entre unidades do negócio
A métrica também pode ajudar bancos a comparar a eficiência de cada unidade de negócio na utilização de capital. Ou seja, uma área de corporate banking com RAROC de 25% seria, em tese, um melhor destino para o capital marginal do que uma área de varejo com RAROC de 17%, embora a decisão final deva considerar também fatores como diversificação e posicionamento estratégico.
Decisões estratégicas
A ideia de entrar ou sair de um determinado segmento de mercado pode ser avaliada por meio do RAROC projetado. Se o retorno estimado para uma nova linha de crédito fica abaixo do custo de capital mesmo em cenários otimistas, o banco tem uma base quantitativa para declinar da oportunidade. Da mesma forma, carteiras e segmentos que apresentam RAROC persistentemente abaixo do custo de capital são candidatos a desinvestimento por parte do banco.
Os riscos do modelo
Nesse artigo, assumimos que sabemos calcular PD, LGD e EAD com precisão. Na prática, esses parâmetros saem de modelos estatísticos que podem errar. No caso da empresa Itaú, o banco mantém uma governança formal de modelos, controlando mudanças metodológicas e realizando backtestings periódicos. Por exemplo, o próprio banco divulga uma tabela que compara as PDs estimadas com as taxas de default efetivamente observadas:
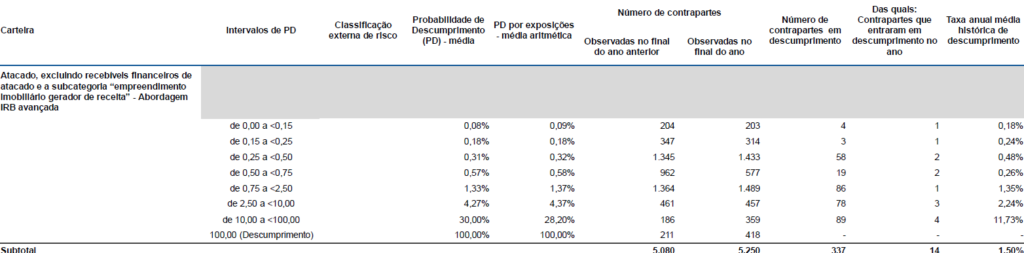
Entre outros problemas, o RAROC também ignora o benefício de correlação imperfeita da carteira. Isso significa que os benefícios da diversificação da carteira do banco são ignorados e, consequentemente, o capital alocado em cada operação é superdimensionado (ao menos, esse é um “defeito” que causa mais conservadorismo ao sistema financeiro).
Por fim, é importante lembrar que os modelos já falharam anteriormente, como na crise de 2008, onde estavam calibrados com dados de “tempos de bonança” que assumiam correlações que desapareceram, assim sendo, o risco de cauda foi simplesmente subestimado pelas instituições financeiras.
O RAROC, criado nos anos 1970 pela Bankers Trust, evoluiu de uma ferramenta interna de alocação de capital para um pilar central da gestão bancária moderna. Os princípios estabelecidos por ele orientam decisões de capital tanto de instituições financeiras de grandíssimo porte quanto de agentes menores, seguindo os mesmos preceitos: capital econômico proporcional ao risco, perda esperada incorporada ao preço e governança de modelos garantindo a integridade dos cálculos.
Podemos concluir que o RAROC, apesar de sua aparente simplicidade, só funciona dentro de um ecossistema sofisticado: apetite de risco bem definido, três linhas de defesa, validação independente de modelos, backtesting periódico e governança profissional. Sem esse arcabouço, a métrica vira um número solto em uma planilha.
Autor: Gustavo Minatto Martins.